
The Cost of the Cloud#
One of my recent projects was to migrate some testing servers from on-premises to Amazon EC2. There were valid reasons for doing so, with the most pressing being to offload the testing workload to the cloud. Testing isn’t run 24/7, so those machines don’t need to be online all the time taking up server space. They can be dynamically provisioned en masse on AWS, and terminated once testing is complete. In doing this, we wouldn’t have dormant machines taking up space, and we wouldn’t incur extra costs, in theory.
In reality, the EC2 bill last month for these servers was nearly $1,000 more than expected (I’m using this number as a placeholder). I’m acutely aware of AWS horror stories where users woke up to surprises of $5 million on their cloud bill, but luckily, bitcoin mining hadn’t happened to us. So what really did?
Exploring the Cost#
First, let’s see what we should actually be getting billed for. There are multiple dimensions to the billing of Amazon EC2 instances. Most work on a per-hour or per-second basis1 such as those below:
- The instance type (CPU, memory, network performance)
- The operating system of the instance (Linux, Windows, etc.)
- The geographical region that the instance is running in
There are many more factors than these, and those can all be found on the EC2 Pricing page. In my case, I started by reviewing the instance types we were using. Perhaps I made a typo and picked some nice and expensive machine learning instances by mistake. I loaded Cost Explorer, and sorted by instance type. For obvious reasons I won’t display the real bill and usage, so we’ll just use my dummy account to show what Cost Explorer would look like. You can access Cost Explorer in your own AWS account via the Billing Console.
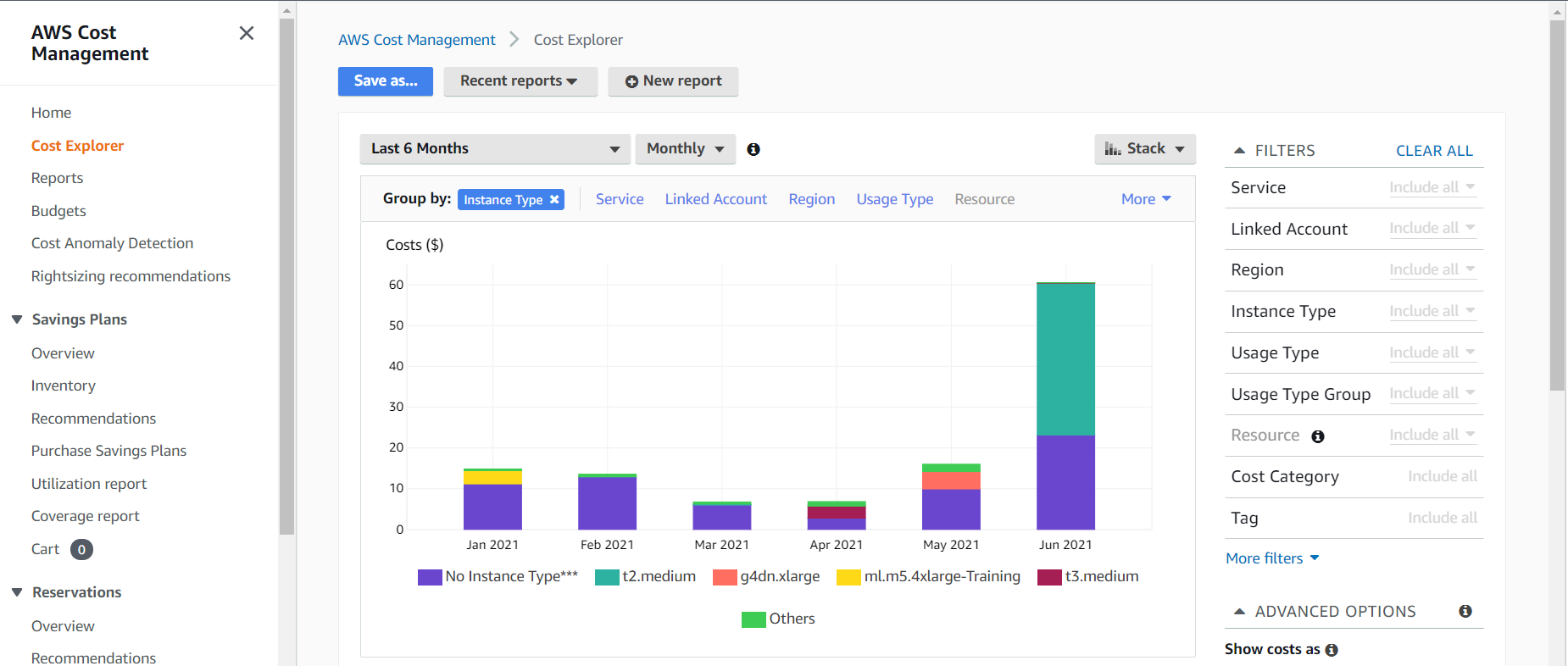
See that “No Instance Type***” instance type? On the real bill, that number was exactly the extra $1,000+. I can further filter on this data using the Service filter. Selecting “EC2-Other” gets closer to the answer.
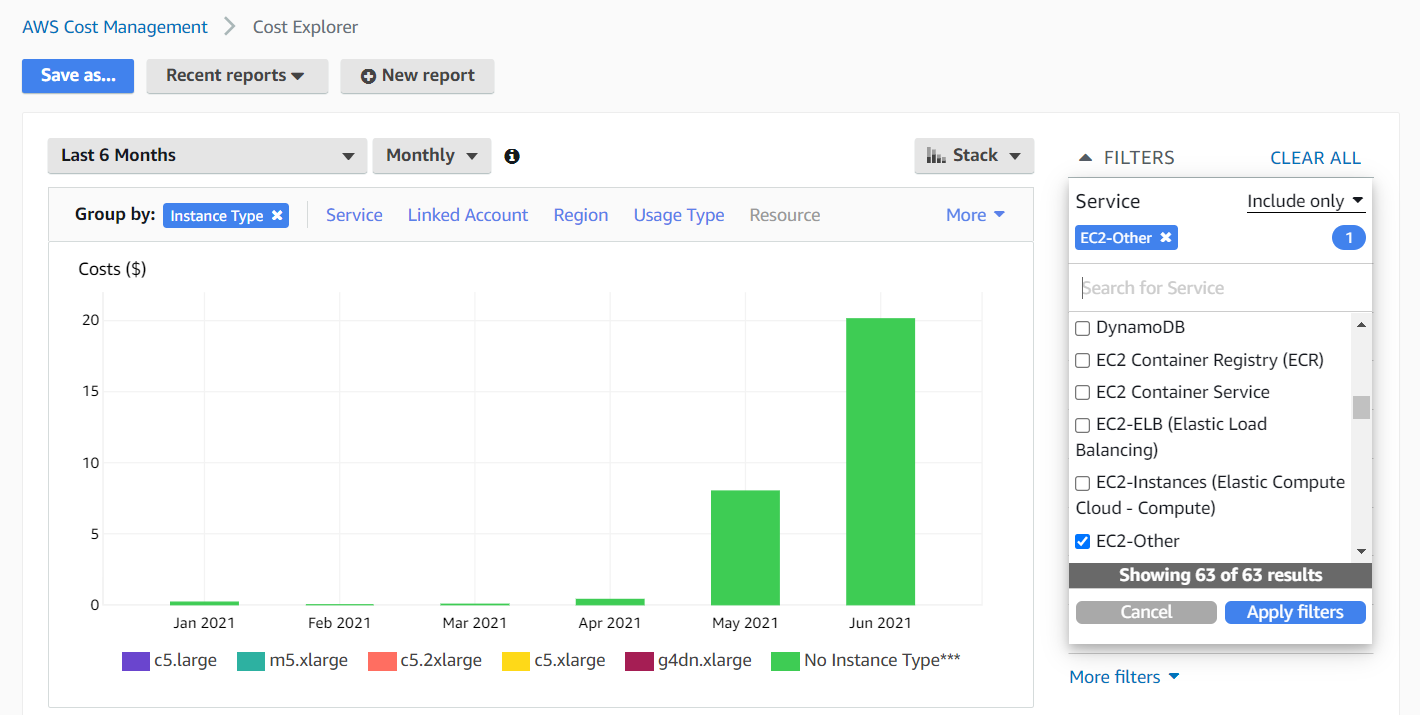
Notice how only the "No Instance Type" instance type remains after the filter. We can finally shift to group by usage type, since instance type will not do us much good from now on.
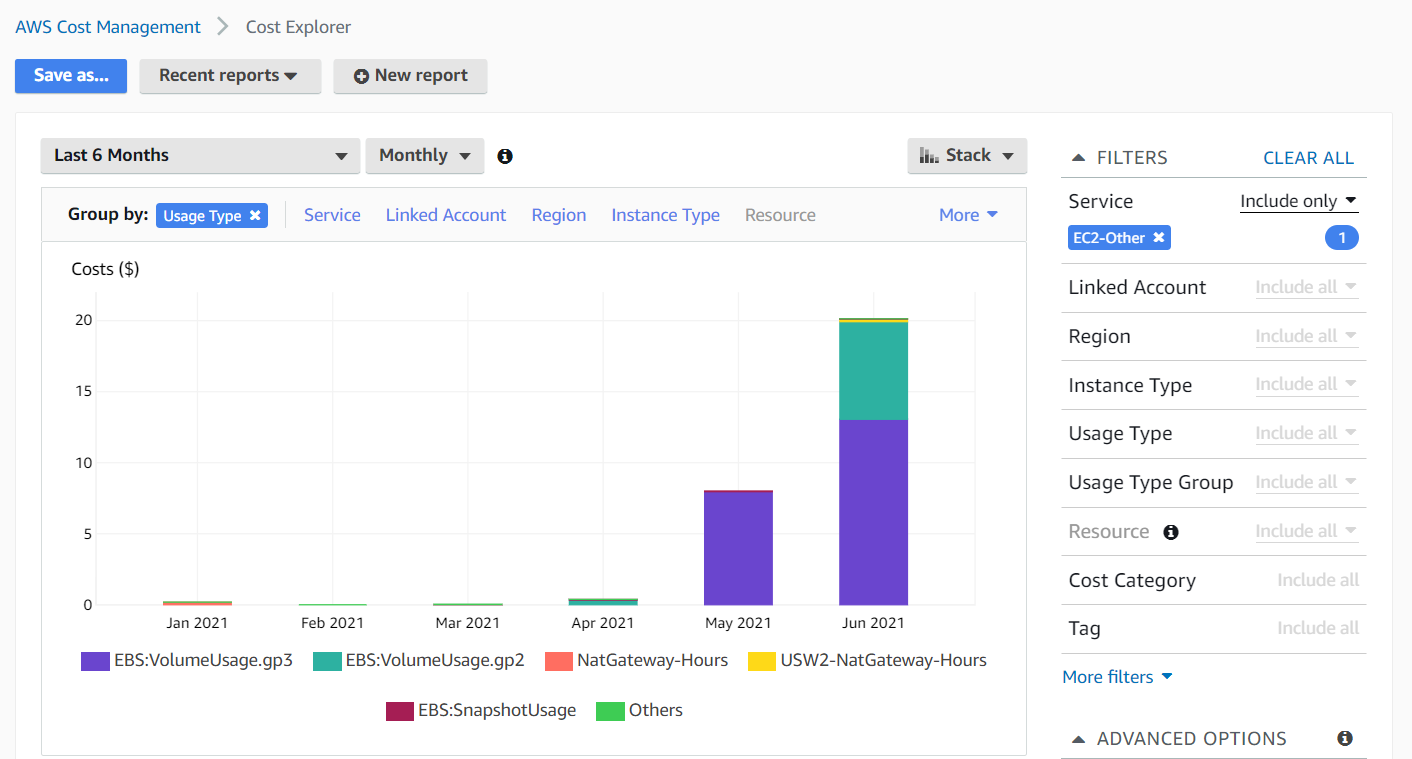
And here we see that VolumeUsage is the major culprit. Just like this diagram, we indeed had the storage volumes of each and every instance lying around after the instance itself was terminated. About 1,336 to be exact. But shouldn’t these have been deleted along with the instances? In select cases like ours, nope.
Custom AMI Problems#
I mentioned earlier that this was a migration project, so I had to import our
custom Linux and Windows machines into AWS as AMIs first. These AMIs are what
constitute the volume (filesystem storage) for an instance. AMIs also have
an attribute called DeleteOnTermination, which if set to False, will not
delete the volume if the instance is deleted.
If this attribute was set to True, or not set at all, each volume would have
been deleted alongside its instance2. It seems that in our case, AWS set this
property to False while importing, and it’s not possible to change the
property once an AMI is made. This makes it easy to rack up volume usage costs
without even realizing it. I had also been using an automation tool called
SaltStack
to spin up hundreds of machines at a time, so this just exacerbated the issue.
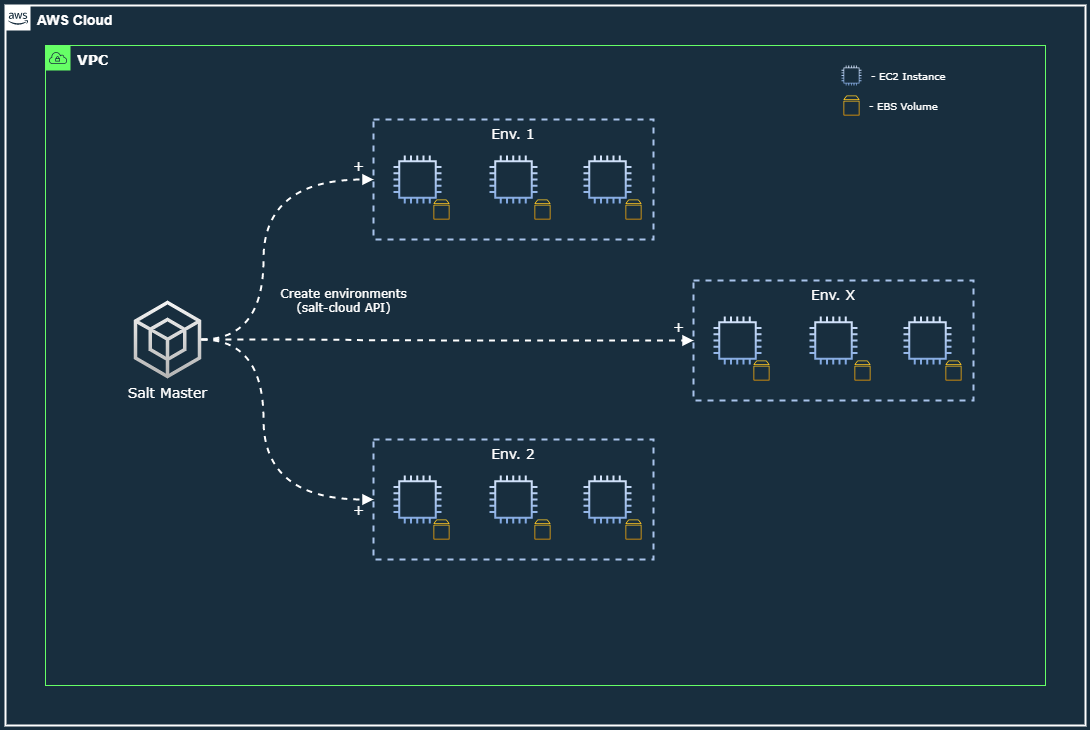
Dynamic provisioning of EC2 instances with Salt, along with their storage volumes.
A feature of Salt is that it allows you to define your servers as code templates, and spin them up for real on cloud hosts. Using one template like the one below, one can spawn 1000 copies of identical machines:
1my-linux-server:
2 provider: ec2-provider
3 image: ami-1234567890
4 size: t2.medium
5 ssh_username: ec2-user
6 ssh_interface: public_ips
7 tag: {'Name': 'My Linux Server', 'Project': 'Saving Money'}
I’ll likely write an article on Salt later, as I’ve learned some tricks and frustrations over the years.
So how was the problem fixed?#
- First and foremost, delete all 1,336 lingering volumes.
- There’s a specific parameter that can be set in the Salt template that creates the VM.
It’s named
del_root_vol_on_destroy, and we can set it toTrue. This setting forces the attached volume to be terminated if its partner VM is terminated. In fact, according to Salt’s documentation, this is recommended as Custom AMIs have a tendency of havingDeleteOnTerminationset to false.
So below is the modified Salt template:
1my-linux-server:
2 provider: ec2-provider
3 image: ami-1234567890
4 size: t2.medium
5 ssh_username: ec2-user
6 ssh_interface: public_ips
7 tag: {'Name': 'My Linux Server', 'Project': 'Money Saved'}
8 del_root_vol_on_destroy: True
Solved with a quick search through the documentation, and since then we haven’t had any wild volume costs. Including orphaned volumes, AWS has a list of common unexpected charges and how to avoid them. So … yeah, this was a fire drill for Cost Explorer. I hope this was helpful, and that you won’t need to run fire drills any time soon.
Per-Second Billing is only eligible for Amazon Linux, Windows, and Ubuntu operating systems. For Per-Hour instances, a partial-hour of use will be rounded up. https://aws.amazon.com/ec2/pricing/#Per_Second_Billing ↩︎
If the attribute is unset, and if the volume in question is the root volume, it will be deleted by default. We had only been working with a single volume per instance, so this worked for us. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/terminating-instances.html#preserving-volumes-on-termination ↩︎